The sensory evolution of AI—How integrating sight, sound, and text is creating the first truly “World-Aware” models.
For the past several years, the tech world was captivated by Large Language Models (LLMs). While impressive, these systems were essentially “brains in a vat”—highly intelligent but limited to the world of text. In 2026, that limitation has been shattered. The rise of Multimodal Machine Learning has introduced a new generation of models that don’t just process words; they understand the physical world through a fusion of visual, auditory, and sensor-based data.
According to top-tier research from OpenAI, Google DeepMind, and Meta’s AI Lab, the transition to multimodality is not just an upgrade—it is a fundamental requirement for achieving Artificial General Intelligence (AGI). By training models on diverse data types simultaneously, we are moving away from narrow linguistic patterns and toward a holistic understanding of context and reality.
The Limitation of “Text-Only” Intelligence
To understand why we are moving beyond LLMs, one must understand the “Linguistic Gap.” A model trained only on text can describe a sunset perfectly, but it has no concept of what “light” actually looks like or how “warmth” feels. This lack of sensory grounding leads to the common “hallucinations” seen in earlier models.
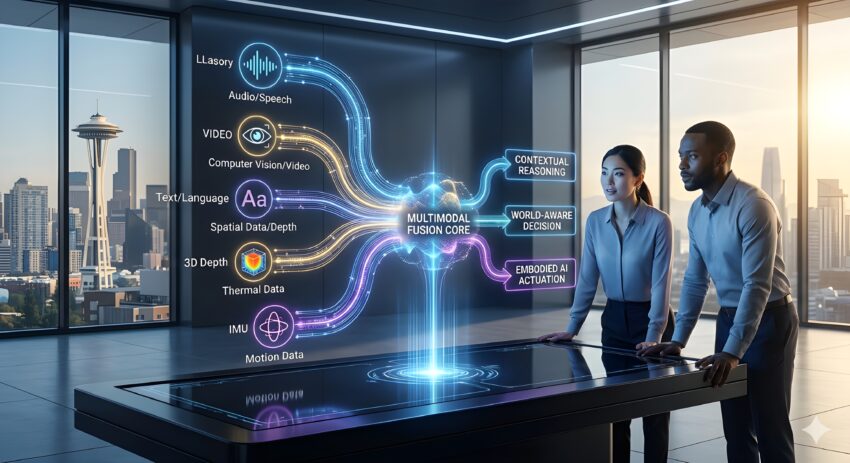
In 2026, Machine Learning Workloads are increasingly shifting toward “Joint Embedding Architectures.” These systems allow the AI to map a word (like “hammer”) to its visual image, its sound when hitting a nail, and its physical properties in a 3D space. This creates a much more robust representation of the concept, leading to higher accuracy and better reasoning.
The Core Architecture: Fusion and Alignment
The secret behind multimodal success lies in how different data types are brought together. In the early days, “Late Fusion” was common—models would process an image and a text caption separately and then combine the results at the very end. This was inefficient.
Today, we use “Early Fusion” or “Cross-Attention” mechanisms. In these Deep Learning Algorithms, the visual tokens and text tokens are processed in the same mathematical space from the beginning. If the model sees a video of a car crash, it doesn’t just “see” pixels; it immediately aligns those pixels with the concepts of “impact,” “velocity,” and “insurance liability.” This cross-modal alignment is what allows AI to perform complex tasks, such as diagnosing medical conditions from a combination of a patient’s chart (text), an MRI (image), and a heart-rate monitor (time-series data).
Multimodal AI in the Enterprise: The ROI of “Sight”
For businesses, the move beyond LLMs is a game-changer for Digital Transformation Services. Industries that were previously “AI-resistant” because their data wasn’t primarily text are now leading the charge.
- Manufacturing and Logistics: Multimodal agents now monitor factory floors. They combine visual feeds from cameras with acoustic data from machinery to predict failures before they happen. If a turbine sounds “off” and the thermal camera shows a heat spike, the AI can autonomously trigger a maintenance ticket.
- Retail and E-commerce: Gone are the days of simple text searches. Consumers in 2026 use “Visual-Semantic Search.” You can upload a photo of a partially damaged vintage chair, and the AI will find the exact model, suggest replacement fabric that matches the texture in the photo, and provide a video tutorial on how to repair it.
- Legal and Compliance: Modern Regulatory Compliance Software now analyzes more than just contracts. It scans video footage of board meetings, analyzes the tone of voice in audio recordings, and cross-references these with written documentation to detect potential ethical breaches or “red flags” that text alone would miss.
The Role of Custom Multimodal Development
As these systems become more complex, the “one-size-fits-all” model is fading. Companies are investing in Custom AI Development to create multimodal models tailored to their specific “sensory” needs. A satellite imagery company doesn’t need a model that understands audio; it needs a model that combines multispectral image data with historical climate records.
To manage these sophisticated models, high-performance Cloud Computing Architecture has become a necessity. Processing video, audio, and text simultaneously requires massive bandwidth and specialized GPU clusters (like the NVIDIA H200 or B100 series). Furthermore, Edge Computing Services are being deployed to handle multimodal inference on-site, allowing for real-time visual processing in autonomous vehicles and robotics without the latency of the cloud.
The Ethics of “Omni-Present” Intelligence
With the ability to “see” and “hear,” the stakes for AI safety have never been higher. The integration of AI Ethics & Governance is no longer optional. Multimodal models can inadvertently pick up on subtle biases in visual data—such as gender or racial stereotypes in stock photography—and amplify them in their reasoning.
Governance frameworks in 2026 are focused on “Multimodal Transparency.” This means the AI must be able to explain which piece of data led to a conclusion. Was it a specific sentence in a report, or was it a micro-expression detected in a video interview? Ensuring that these systems remain fair and unbiased is a primary focus for tier-one tech hubs in the United States and the EU.
The Future: Embodied AI and the Physical World
The ultimate destination of the “Beyond LLMs” movement is Embodied AI. This is where multimodal models are placed into robotic bodies. When a model understands the relationship between text instructions (“pick up the red mug”), visual data (identifying the mug’s location), and haptic data (knowing how much pressure to apply so the mug doesn’t break), we have reached a new era of robotics.
In this stage of Future Tech & Digital Evolution, AI is no longer something behind a screen. It is a physical presence that can navigate the world with the same sensory fluency as a human. This will revolutionize home care, disaster recovery, and space exploration.
Conclusion: Embracing the Multimodal Era
The transition from LLMs to Multimodal Machine Learning marks the end of AI’s “infancy.” We have taught machines to speak; now, we are teaching them to experience. For business leaders and developers, the message is clear: if your AI strategy is only focused on text, you are missing 90% of the world’s data.
By leveraging Data Engineering Services to clean and align multimodal datasets and investing in Intelligent Software Ecosystems, organizations can build models that truly “understand” their environment. The rise of multimodality isn’t just a trend—it’s the sensory awakening of artificial intelligence.